

The Extended Cinematic Vision: WAN 2.2 Workflow Breakdown
Hi, this is CCS, today I want to give you a deep dive into my latest extended video generation workflow using the formidable WAN 2.2 model. This setup isn’t about generating a quick clip; it’s a systematic approach to crafting long-form, high-quality, and visually consistent cinematic sequences from a single initial image, followed by interpolation and a final upscale pass to lock in the detail. Think of it as constructing a miniature, animated film—layer by painstaking layer.
P.s. The goblin walking in the video is one of my elven characters from the fantasy project MITOLOGIA ELFICA —a film project we are currently building, thanks in part to our custom finetuned models, LoRAs, UNREAL and other magic 🙂
More updates on this coming soon.
Follow me here for any update or making of.
Phase 1: From Still Image to Cinematic Segment Chain
The core of this workflow is the ability to generate a continuous video sequence by chaining multiple segments, ensuring visual coherence across the transitions.
-
Preparation and Spatial Framing: We start by loading an initial source image. Immediately, the image is passed to a Resolution Manager to define its dimensions for the video. Crucially, the image is also resized and pre-processed (the height is resized from 832 to 720 and the width from 480 to 480) and stored in a temporary buffer, ready to feed the first video generation module. This preparation is essential for consistent video output and setting the stage for the rest of the chain.
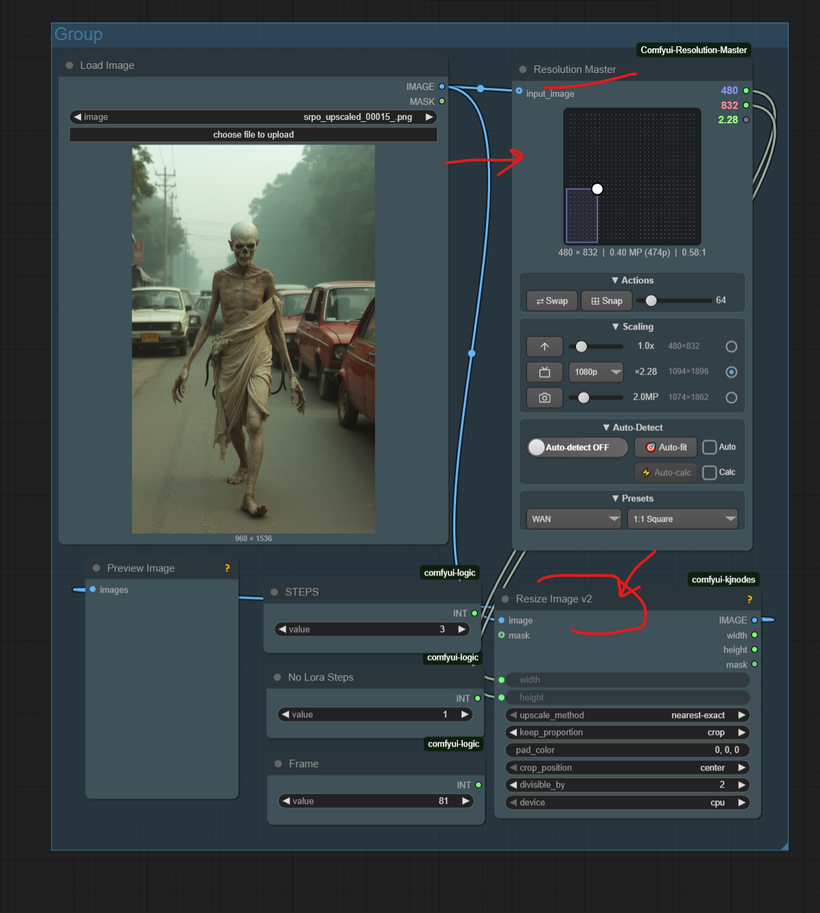
-
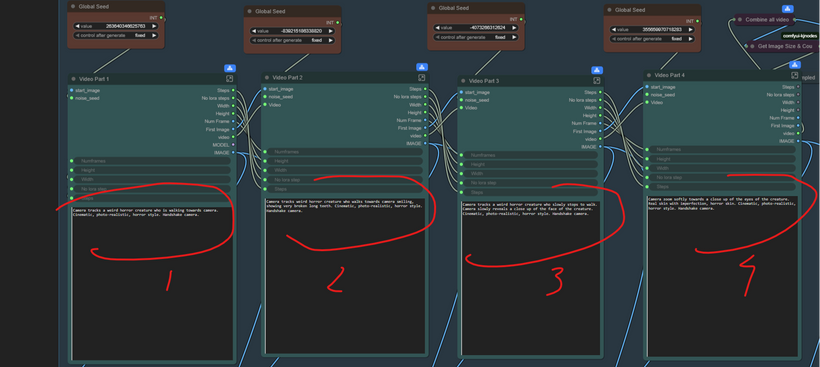
The Looping Generation Engine (The “Parts”): The workflow is structured around a chain of four identical Sequential Video Generation modules (your “Video Parts”). This is where the magic of extension happens.
-
The first module takes the prepared still image as its starting frame. It is supplied with the core Model (WAN 2.2), the VAEs, CLIP encoders, and most importantly, an initial Noise Seed along with the desired total number of frames for the entire video , and the specific steps/no-Lora steps for the sampling process.
-
A precise descriptive prompt, acting as your direction, sets the motion and narrative (e.g., “Camera tracks a weird horror creature who is walking towards camera…”).
-
The secret sauce is the chaining: the final frame of the output from the first module becomes the starting image for the second module. This image-to-video consistency lock is vital to avoid jarring jumps.
-
This process is repeated through the second, third, and fourth modules. Each module in the chain uses a unique Noise Seed to introduce variation and extend the narrative, and each uses the final frame of the previous segment as its anchor image.
-
-
Finalizing the Base Video: All four video segments (each an image batch) are collected by a Video Batch Concatenation mechanism. This essentially stitches the four sequential segments together into one single, long-form video image batch.
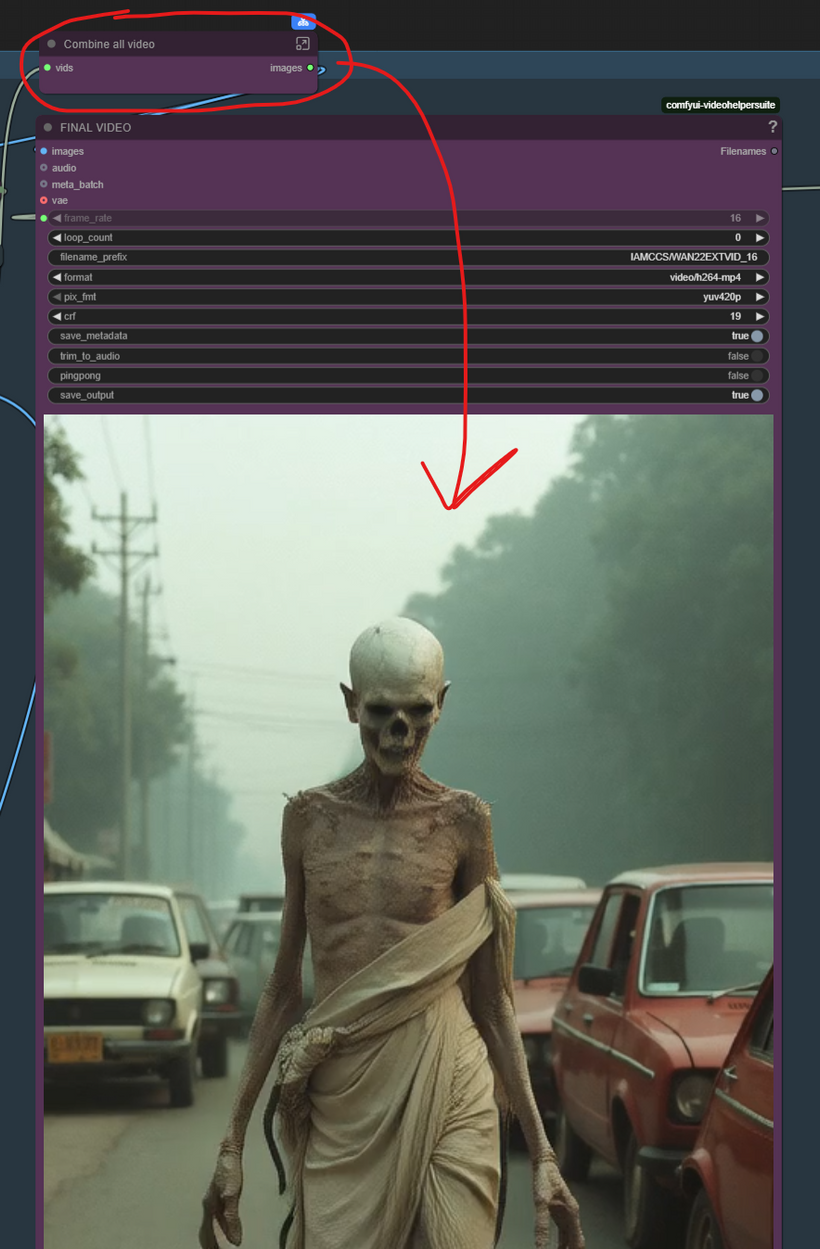
Phase 2: Frame Interpolation for Smooth Motion
Once the master image batch is assembled, the fluidity of the motion is addressed in the Interpolation section. Since the base video was generated at a low framerate (implied by the number of steps vs. total frames), we need to fill in the gaps.
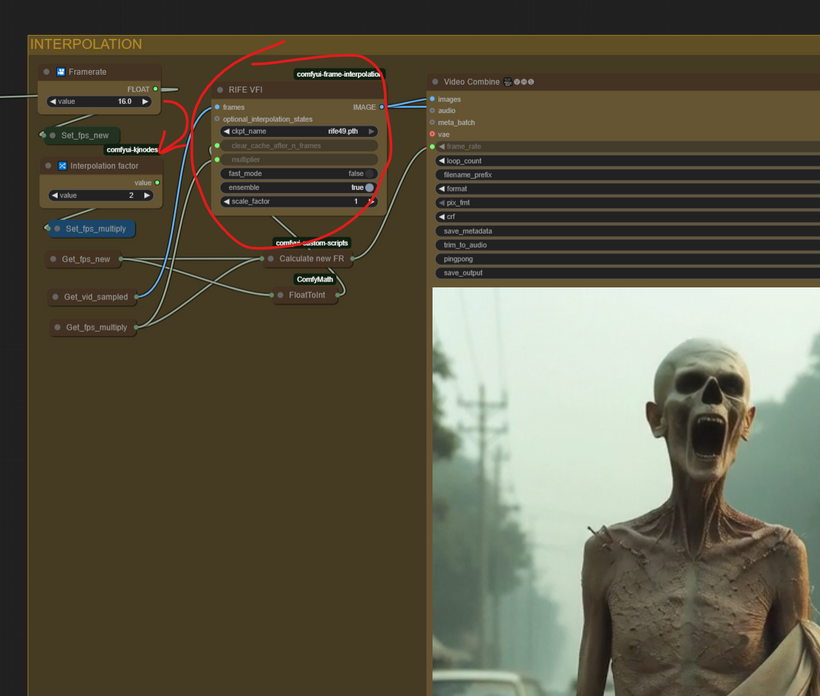
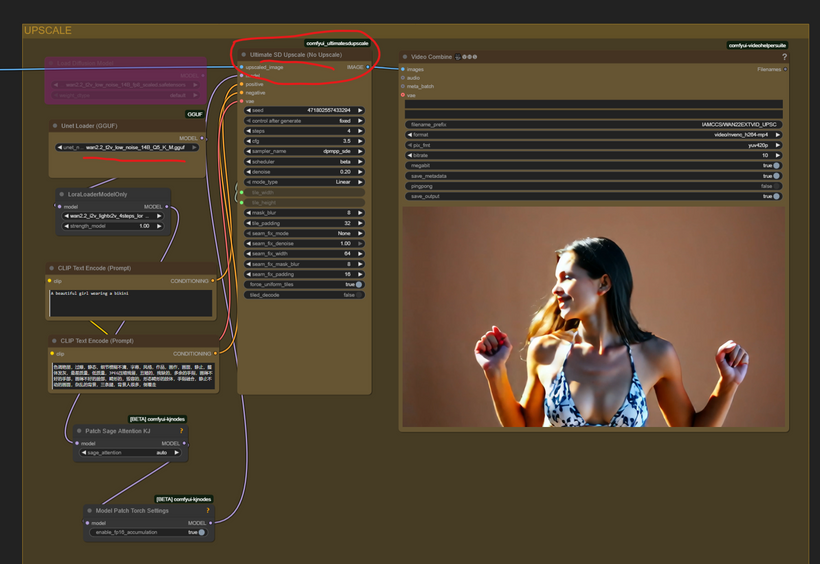
Phase 3: The Ultimate Quality Polish (Tiled Upscale)
The third phase is a targeted quality enhancement pass to refine the interpolated video, ensuring high detail without prohibitive VRAM usage.
-
Model and Prompt Setup: The video is prepared for a final diffusion pass. The workflow loads a specialized WAN 2.2 Unet (GGUF version, which is likely faster for inference) and a Lora for lightning-fast 4-step generation. The CLIP encoder is loaded to process the final Positive Prompt and the comprehensive Chinese Negative Prompt (to counteract common AI artifacts). Finally, a VAE is loaded to handle the latent space operations.
-
Tiled Diffusion & Upscaling Simulation: The interpolated video is passed to the Ultimate SD Upscale equivalent node, but configured to perform an Upscale-Free pass. This node is traditionally for upscaling, but when the output resolution is the same as the input (e.g., 480×832, derived dynamically from the preparation stage), it functions as a highly effective Tiled Diffusion engine.
-
It breaks the large image into smaller tiles (tile_width, tile_height), processes the diffusion pass on each tile using the new model and prompts, and then seamlessly stitches them back together. This localized processing adds incredible detail and coherence at the final output resolution.
-
-
Final Video Encoding: The processed, high-quality image batch is finally encoded into the definitive video file using a separate Video Combiner with an optimized format (video/nvenc_h264-mp4 at 10 Megabit bitrate).
Post-Production: Frame Selection
A quick final step isolates the very last frame from each of your four original video segments and the final tiled-diffusion video. These “Final Frame Selectors” ensure you have a clean, high-fidelity still image for each key narrative moment to re-generate another video from it if You are unhappy of some part resuly. The frames are also perfect for thumbnails, previews, or simply . The selected frames are also saved as images to a specific folder (IAMCCS/FINALFRAMES).
FINAL THOUGHTS
Of course, you can swap out the LoRAs inside the video generation segments (in the subgraphs). In fact, it seems that removing the acceleration provided by the LoRAs makes the image look real-time instead of slow motion, but it all depends on many unpredictable circumstances. For example, I often achieved good motion results using the light2v t2v LoRA from WAN 2.1 and not the specific WAN 2.2 one—you have to experiment to figure out what works best for you!
I’ve attached here the initial image that I generated of this peculiar creature 🙂 and the workflow itself! Happy creating, and I’ll see you in the next post!
And don’t forget to subscribe and follow me to support my work!

