
Hi folks, this is CCS.
Another add to the LTX-2.3 workflow family: T/I2V with ID-LoRA + Reference Audio — voice-preserved talking-character generation, open source, inside ComfyUI.
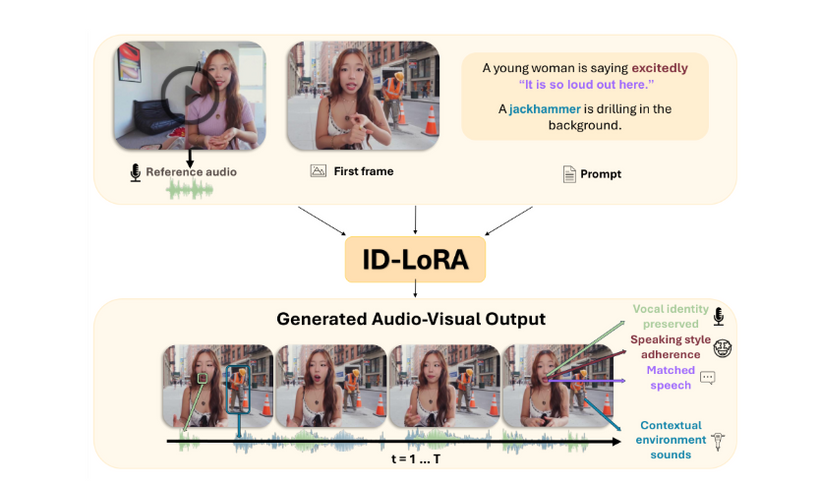
What the pipeline does
You load a reference image (or skip it for pure T2V), write a structured prompt with [VISUAL], [SPEECH], and [SOUND] tags, and optionally feed a short 5-second audio clip to anchor the speaker’s voice identity. The model generates a synchronized audio+video clip where the face, lip movement, and vocal timbre stay coherent throughout.
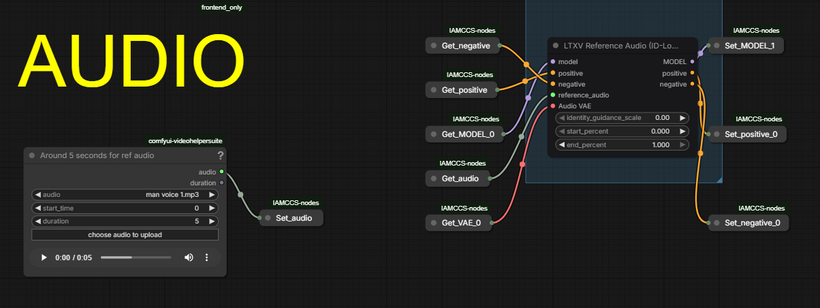
The reference audio trick
The LTXVReferenceAudio node encodes your audio clip into a conditioning signal injected into the shared AV latent stream. It does not replay the sample — it extracts persistent vocal traits (timbre, resonance, speaking color) and reuses them in the newly generated dialogue. ~5 seconds of clean recording is enough.
What you need
For LTX-2.3 models downloads and other info, refer to my previous posts:
[VID] LTX-2.3: The New King of AI Video? 🚀 Full Workflow & Test | Patreon
As for the LoRA ID reference links:
https://huggingface.co/AviadDahan/LTX-2.3-ID-LoRA-CelebVHQ-3K
https://huggingface.co/AviadDahan/LTX-2.3-ID-LoRA-TalkVid-3K
The workflow supports both high and low VRAM paths, tiled decoding, and the VAE Decode → Disk node for very long or memory-constrained renders.
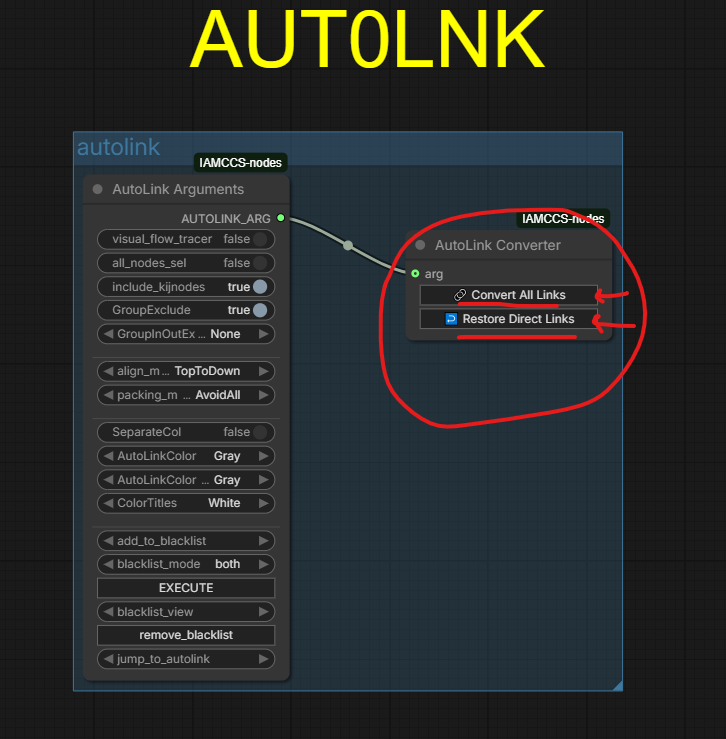
For a clean workflow, as always, click “convert all links” in the autolink module.
Thanks again for the support, guys—let’s keep this journey going together! This month there will be even more incredible updates from the AI image/video generation world—stay tuned!
More soon. — CCS

